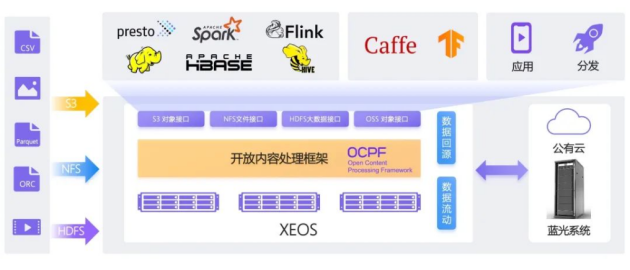
目前,先进组织都已经建立或者正在规划建设自己的数据湖,用来支撑大数据分析业务。存储作为数据湖的底座,业界有两个技术流派:一是基于分布式文件,二是基于对象存储。
为满足大数据不同场景需求,XSKY 星辰天合基于对象存储、文件存储不同存储类型,提供不同大数据存算分离方案。
在上一篇文章中,我们详细介绍了基于分布式文件存储的大数据方案,大数据存算分离方案上篇:基于分布式文件的数据就地分析。
本文是XSKY星辰天合大数据存算分离解决方案的下篇,详细介绍基于对象存储的大数据方案。
数据湖发展趋势
数据湖最早是由 Pentaho 公司的创始人兼 CTO 詹姆斯・迪克森在2010年10月纽约Hadoop World大会上提出来的,当时的目标是为了推广Hadoop。十几年过去了,Hadoop 已逐渐退温,但数据湖还在大数据时代持续火热。
数据湖即指数据湖存储,可以集中式存储各种类型数据,包括:结构化、半结构化和非结构化数据。数据可以按原始形态直接存储(无需先对数据进行结构化处理),覆盖多种类型数据输入源。数据湖无缝对接多种计算分析平台,对Hadoop生态支持良好,存储在数据湖中的数据可以直接对其进行数据分析、处理、查询,通过对数据深入挖掘与分析,洞察数据中蕴含的价值。
目前面向大数据的数据湖存储,像分布式文件系统和基于S3的对象存储都属于这个范畴,今天聚焦对象存储的数据湖方案。
常见的对象存储对接大数据方案
社区S3A方案
原生的Hadoop中包含一个的S3A连接器,基于Amazon Web Services (AWS) SDK实现的。Hadoop S3A允许Hadoop集群连接到任何与S3兼容的对象存储。
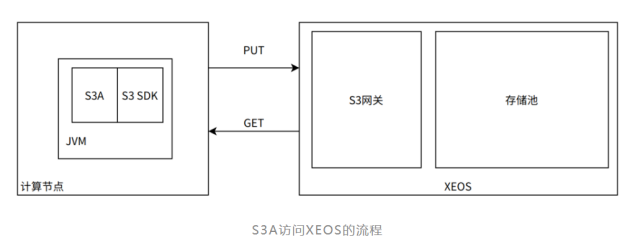
通过上图可以看到Hadoop应用通过S3A客户端上传数据时,需要调用S3 SDK把请求封装成HTTP然后发送给XEOS的S3网关,通过S3网关将数据写入存储集群,从而达到数据上传的目的。下载文件也是一样的道理。
S3A虽然可以实现基本的计算和存储分离,但基本架构和协议兼容性上还是存在一些问题:
由于基于标准的S3 SDK实现,无法利用各个存储系统之间的特性差异进行针对性优化
S3A因为通过S3 SDK来实现,所以并不支持标准Hadoop文件系统的append、flush等操作
S3A将文件接收到本机硬盘后,再并发的分片上传到对象存储,对于本地磁盘IO有较大开销,同时如果出现断电、坏盘等异常,会造成已写入到本地未回传的数据无法访问
元数据加速方案

由于对象存储元key-value元数据机制的限制,在hadoop场景中当有大量元数据相关访问或者操作时,元数据服务可能成为hadoop应用性能的瓶颈,因此业界出现了在对象存储系统外部维护专用的元数据服务的方案,如Alluxio等方案,他们通过独立的元数据服务来向hadoop提供高性能的元数据访问,同时通过内部机制与对象存储实现元数据的最终一致性。
该类型方案能为元数据性能带来较大的提升,但同时需要引入独立的元数据服务,同时存在着以下几类挑战:
独立元数据与对象存储实际数据的一致性管理
独立元数据引入的资源开销,如CPU、SSD等
独立元数据后与对象存储数据的互通方案
XSKY 星辰天合基于对象存储的大数据方案――XHFS
方案介绍
XHFS借鉴了S3A的实现方案,在计算端集成了XHFS模块,XHFS实现了Hadoop FileSystem的list、delete、rename、mkdir等接口,以及InputStream和OutputStream的XEOS对象读写功能。
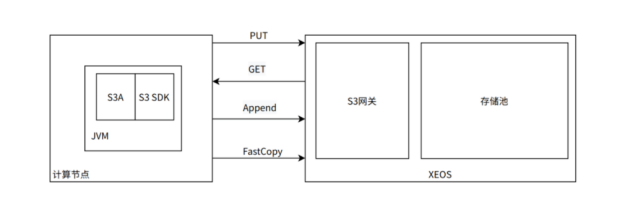
・强一致模型
不同于部分对象存储产品无法提供数据的强一致语义,如并发写入时无法保证一定能读到最新的数据,所以需要应用层利用外部机制进行强一致保障,如引入S3Guard等方案增加复杂度和成本,而XEOS原生提供强一致语义,无需引入复杂的业务逻辑进行强一致保障。
・ 高效重命名
重命名通常对于对象存储是开销较大的动作,但大数据场景利用目录重命名来进行CAS(Compare And Swap,即比较并交换)的操作比较常见,CAS操作即将计算过程数据写入临时目录,在任务结束时进行目录的总体重命名,这就对使用对象存储作为大数据底座的方式带来了比较大的挑战。
XEOS通过存储后端优化,可以实现快速的对象重命名和目录重命名,XHFS利用XEOS内部接口能够向应用提供高效的文件重命名和目录重命名功能。
・高性能写入
XHFS将OutputStream改造为对象追加写的方式,能够提供更高性能的数据写入方式,同时能大幅降低写入过程中断电等异常造成的数据写入失败的数据量。
・hflush、hsync支持
基于XEOS的特性,XHFS可以兼容hflush、hsync等对写入一致性要求严格的语义。
方案优势
・海量存储,数据入湖
全局视角的多存储平台管理,单桶千亿对象规格,分布式存储架构无限横向扩展,无需数据重平衡的整存储池扩容、整存储平台扩容、整站点扩容,大规格EC策略以及数据分层保证数据长期、低成本的存放。
XEOS可以提供S3、NFS、HDFS的数据访问互通,可直接将XEOS直接作为数据源进行大数据分析,无需将数据加载到HDFS后进行分析,从而可以降低成本,提高生产效率。
・数据流动,无缝互通
通过XHFS可将XEOS作为数据存储与流转中心,根据业务数据的特点通过生命周期管理、数据复制让数据按需流动,满足不同组件的性能和成本要求。结合XHFS与HDFS协议互通的特性,打破应用间数据壁垒,助力数据价值挖掘。
・ 拥抱混合云架构
无缝对接公有云,通过生命周期的流动、镜像、归档,轻松上云;通过回源的重定向、代理、镜像、CDN、重建,轻松下云。多种模式按需使用,发挥公有云的成本优势,进一步降低TCO。

摘要:基于数据湖存储的对象大数据XHFS方案,灵活适配S3A大数据生态,全生命周期管理,无缝上下云。

适用场景
・ HDFS与XHFS共存模式
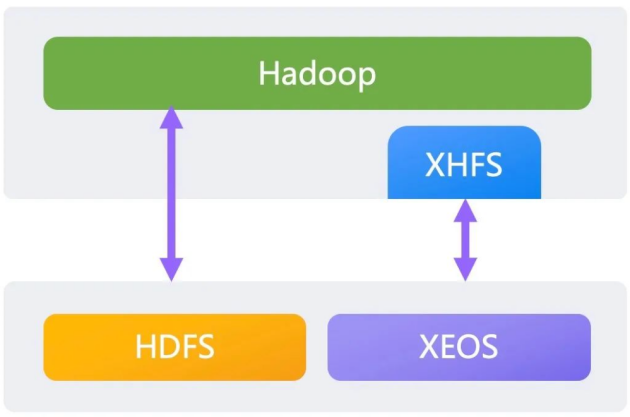
根据数据热度的差异选择不同的存储方案,将温热数据放置在HDFS上满足高性能要求,较冷的数据通过XHFS存放到XEOS满足低成本的长期保存,通过ViewFS提供统一的访问入口,对应用屏蔽存储形态差异。从而实现计算资源的紧密整合,获得高性能、低成本的大数据服务,提升企业数据价值。
・海量冷数据存储和分析
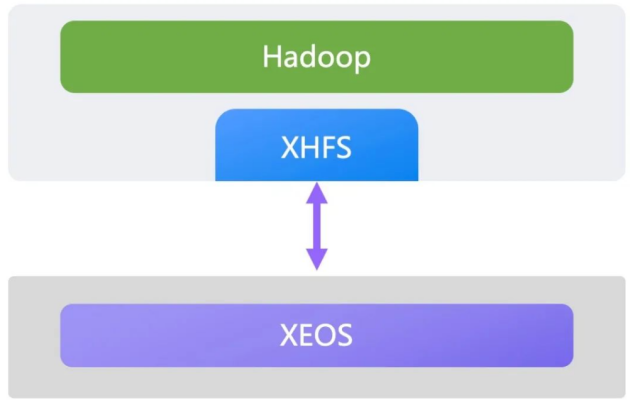
对象存储天然具有高可扩展性和低成本的优势,是作为数据湖存储的不二选择。通过XHFS将海量的HDFS数据存入对象存储,不但能获得更低的存储成本,同时可以实现冷数据的就地分析和管理,大幅降低企业的数据管理复杂度。
成功案例
上海金山区政府政务大数据应用平台

该项目主要包含数据采集系统、大数据平台和大数据可视化展示三个部分,通过平台建设有效利用政务信息数据资源,提升服务质量、降低服务成本、增强决策科学性,为简化审批流程、提高审批和服务效能创造良好基础。实现了业务类型数据资源的采集、稽查及处理,通过数据质量报告对业务和技术规范性做检验指导;实现政务服务基本情况和靓点工作的成果应用展现;完成了政务服务、放管服改革成效与双创环境建设等方面的指标设计,展现政务服务过程的整体图景。
同城双活部署架构
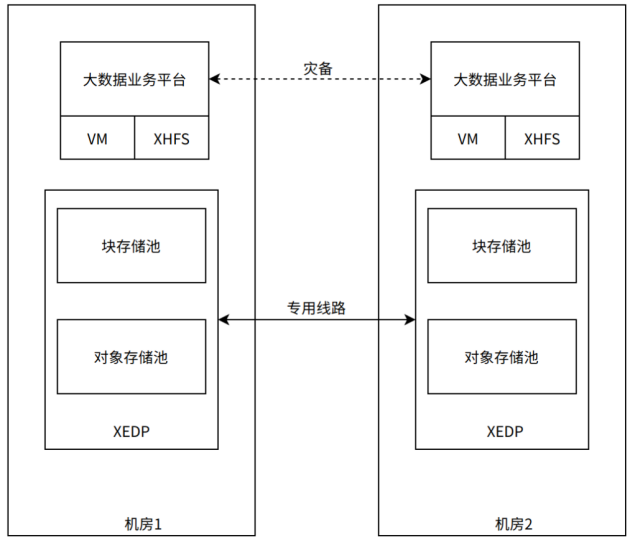
本项目利用XEDP同时交付块存储和对象存储(即XEOS),一个机房一套存储,同时采用同城双活的灾备部署架构,利用XSKY SDS的延展集群功能,实现两个机房的实时数据同步和灾备,通过在存储层实现数据存储和访问的双活,大幅简化应用双活部署难度,实现快速的双活部署
业务逻辑架构
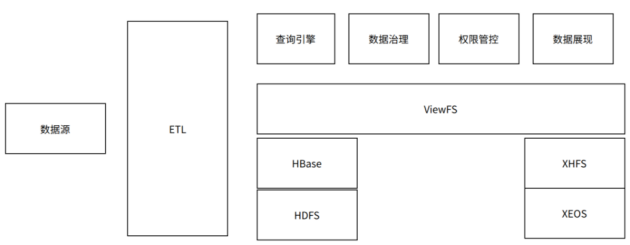
将XEDP/XEOS作为海量存储的数据湖底座,得益于XHFS的兼容性实现了大数据相关组件无缝迁移和访问。方案中XHFS与HDFS共存,将关系型热数据写入HBase,保留小规模HDFS集群以获取更高的本地性能;而对于海量的非结构化数据,通过Sqoop将数据源直接导入XHFS,并由XHFS支撑Hive读写和分析请求,以获取长期海量低成本存储的收益。基于XHFS的数据湖,不但能接入大数据存储,同时能很好的作为web应用平台等数据的存储目标,实现多协议互通访问,达到数据湖存储的目的。
方案优势
XEDP同时交付多种存储方式,一个机房一套存储,满足各类业务需求
快速、便捷实现双活灾备机制
数据统一入湖,数据互通,各组件数据协同生产消费
充分发挥HDFS和对象各自优势,达到最佳TCO